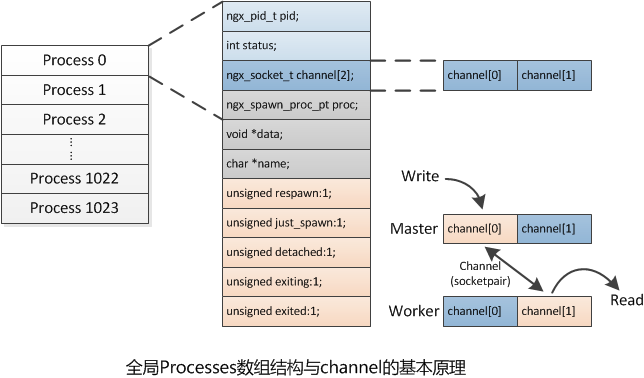
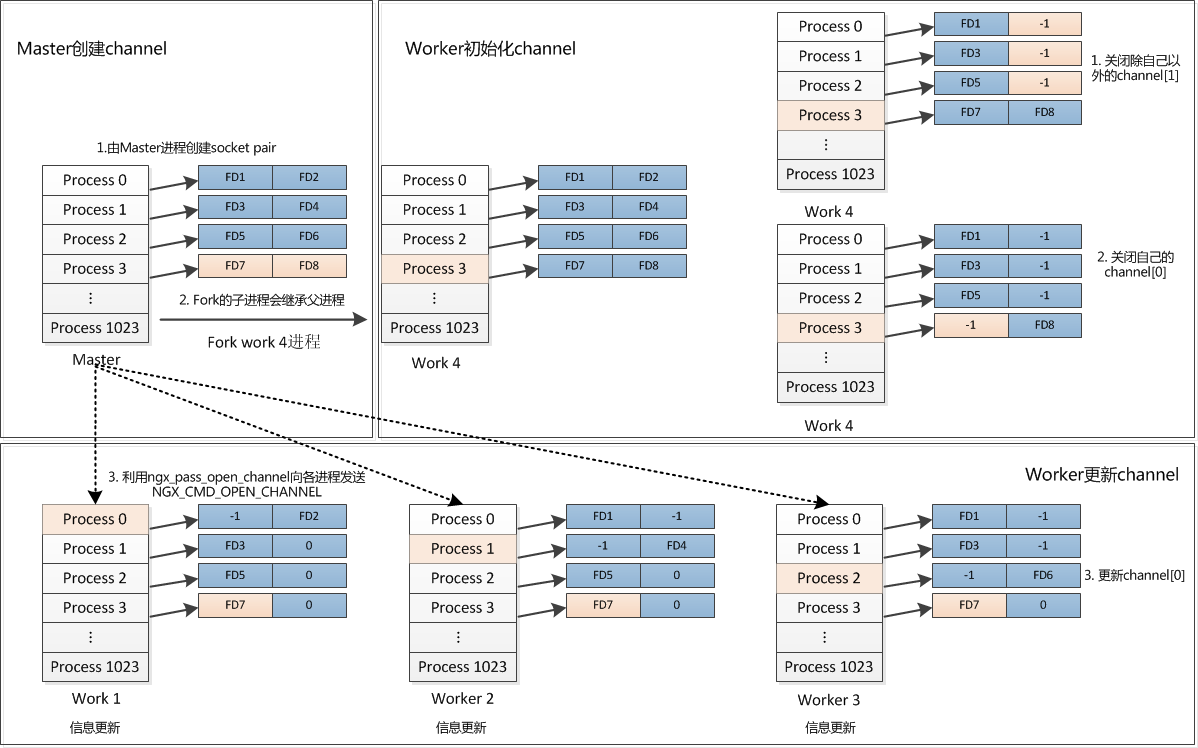
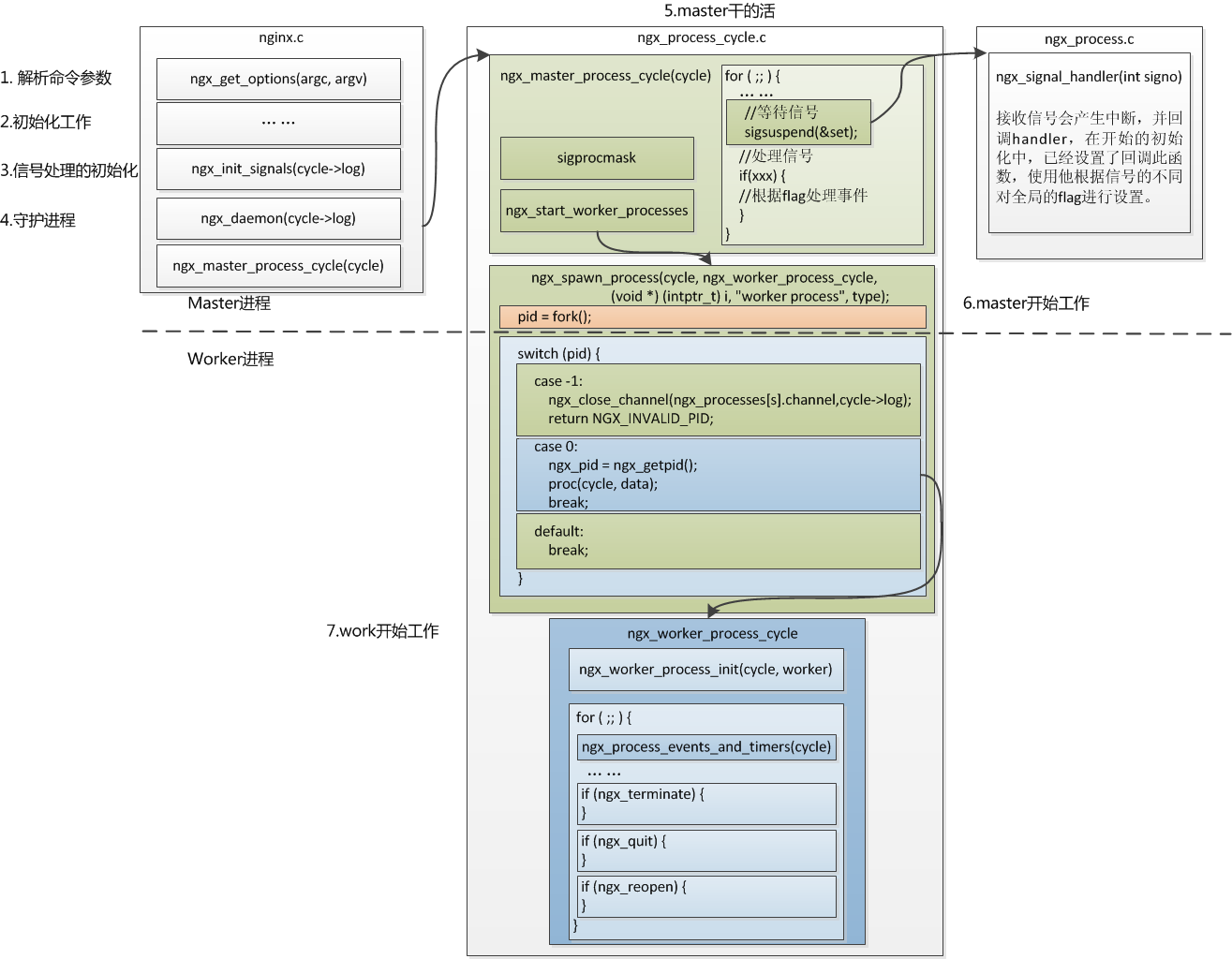
1. 概述因为开始对nginx的模块机制不是很了解,所以开始看事件模块的这部分还是云里来,雾里去的,最后,算是理清了,我觉得应该抓几个核心的数据结构,无论是初始化,还是在事件循环中,都和这些数据结构息息相关。我们需要抓住这两个结构体,搞清楚他们在什么时候初始化,什么时候起作用,这样就可以理清大概的
nginx的事件机制最重要的牵扯到几个结构体,当然niginx的事件的初始化也围绕着这几个模块进行。
2. 事件模块配置的初始化
事件模块配置的初始化,主要是所有事件模块的配置创建与初始化的过程,与事件模块息息相关的是ngx_events_module结构体,定义了对events的“兴趣”,以及初始化events的回调函数ngx_events_block。
首先,最重要的结构体是
ngx_module_t ngx_events_module = { NGX_MODULE_V1, &ngx_events_module_ctx, /* module context */ ngx_events_commands, /* module directives */ NGX_CORE_MODULE, /* module type */ NULL, /* init master */ NULL, /* init module */ NULL, /* init process */ NULL, /* init thread */ NULL, /* exit thread */ NULL, /* exit process */ NULL, /* exit master */ NGX_MODULE_V1_PADDING};
该结构提为nginx的核心模块(NGX_CORE_MODULE),主要用于events配置的解析,那么初始化的时候围绕着这个结构体进行的当然也便是配置解析的相关工作了。
其次,这个模块还需要管理所有时间模块的配置,最后还有就是对各个事件模块的配置进行统一管理。
static ngx_command_t ngx_events_commands[] = { { ngx_string("events"), NGX_MAIN_CONF|NGX_CONF_BLOCK|NGX_CONF_NOARGS, ngx_events_block, 0, 0, NULL }, ngx_null_command};static ngx_core_module_t ngx_events_module_ctx = { ngx_string("events"), NULL, ngx_event_init_conf};
然后再看看ngx_events_module的内容,主要牵扯到的变量有ngx_events_commands、ngx_events_module_ctx,
ngx_events_commands可以理解为告诉解析conf,解析到什么指令,调用什么函数,比如这里就是解析到events指令调用ngx_events_block函数。
ngx_events_module_ctx则是核心模块提供给各种模块实现时提供的接口,事件模块作为核心模块,也需要实现这个接口。
也就是说除了配置文件解析之外,这个模块没有做任何其他事情,让我们来关注一下ngx_events_block。
之前的文章有介绍过nginx的初始化过程,在初始化的时候,会调用ngx_init_cycle函数,而该函数会调用ngx_conf_parse,其中ngx_conf_parse会完成对ngx_events_block的调用,具体是怎么样调用的在以后再学习配置解析的时候再分析。现在只需要知道ngx_events_block调用时机是在ngx_conf_parse的时候就勾勒,重点看下ngx_events_block的实现,ngx_events_block执行过程如图所示,
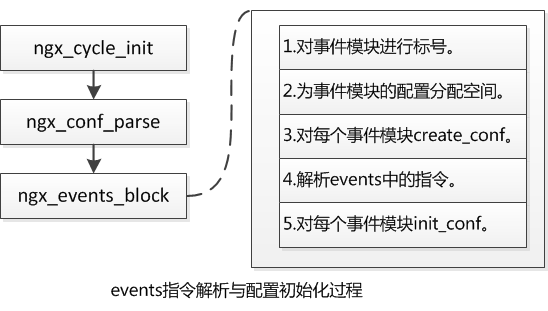
下面将这五步详细介绍一下,
1.对事件模块进行标号。首先在ngx_modules[i]数组里面找到NGX_EVENT_MODULE的变量,之后对每一个事件模块进行标号,也就是说ctx_index表示在相同类型模块中的标号。例如此处的就表示在所有事件模块中的标号。ngx_modules则是一个全局数组,位于obj/ngx_modules.c目录,存储着所有的模块信息。
ngx_event_max_module = 0;for (i = 0; ngx_modules[i]; i++) { if (ngx_modules[i]->type != NGX_EVENT_MODULE) { continue; } ngx_modules[i]->ctx_index = ngx_event_max_module++;}
2.为事件模块的配置分配空间。其次便是给事件模块配置的指针及配置所存储的指针数组分配空间。
//开辟红色部分空间ctx = ngx_pcalloc(cf->pool, sizeof(void *));if (ctx == NULL) { return NGX_CONF_ERROR;}//开辟蓝色部分空间*ctx = ngx_pcalloc(cf->pool, ngx_event_max_module * sizeof(void *));if (*ctx == NULL) { return NGX_CONF_ERROR;}
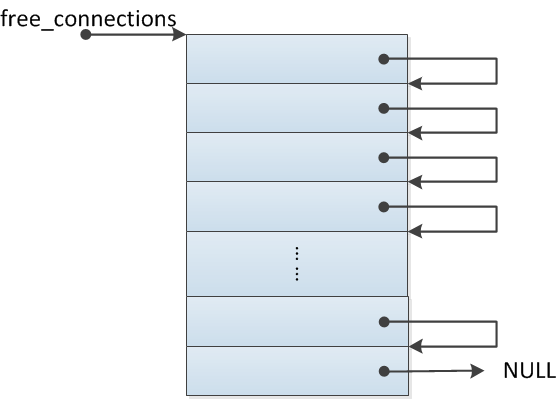
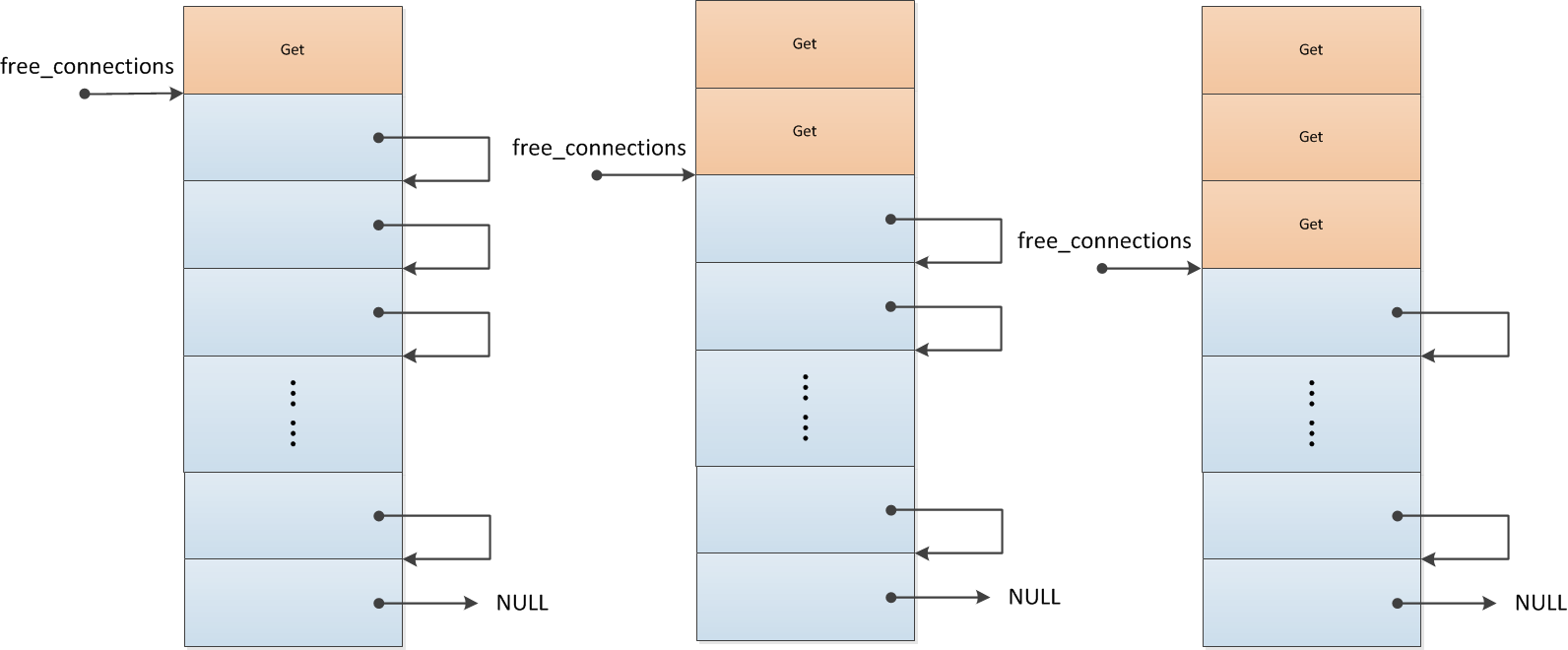
在ngx_cycle_t中有一个conf的四级指针(conf_ctx)。它指向了一个指针数组A(存储着所有核心模块配置结构体指针),A中的指针又指向了另一个指针数组B(假设A中的这个指针是事件模块配置结构体的指针),那么B中就存着事件模块的配置。如图所示
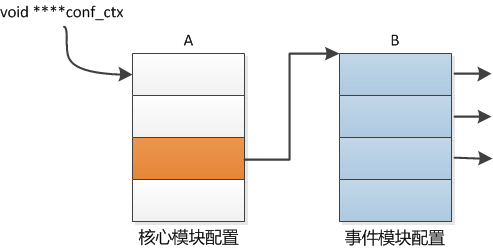
3.对每个事件模块create_conf, 调用每个事件模块中的create_conf方法,m现在指向的就是每个模块的配置内容(即ctx, context,上下文)
for (i = 0; ngx_modules[i]; i++) { if (ngx_modules[i]->type != NGX_EVENT_MODULE) { continue; } m = ngx_modules[i]->ctx; if (m->create_conf) { (*ctx)[ngx_modules[i]->ctx_index] = m->create_conf(cf->cycle); if ((*ctx)[ngx_modules[i]->ctx_index] == NULL) { return NGX_CONF_ERROR; } }}
4.解析events中的指令。调用ngx_conf_parse解析events块中的指令。
5.对每个事件模块init_conf。调用每个事件模块中的init方法
for (i = 0; ngx_modules[i]; i++) { if (ngx_modules[i]->type != NGX_EVENT_MODULE) { continue; } m = ngx_modules[i]->ctx; if (m->init_conf) { rv = m->init_conf(cf->cycle, (*ctx)[ngx_modules[i]->ctx_index]); if (rv != NGX_CONF_OK) { return rv; } }}
完成每个conf的配置。至此,ngx_events_block的工作就完了,总结一下就是负责配置文件中events block的解析。
3. ngx_event_core_module
其次,是ngx_event_core_module这个模块是一个事件类型(NGX_EVENT_MODULE)的模块
ngx_module_t ngx_event_core_module = { NGX_MODULE_V1, &ngx_event_core_module_ctx, /* module context */ ngx_event_core_commands, /* module directives */ NGX_EVENT_MODULE, /* module type */ NULL, /* init master */ ngx_event_module_init, /* init module */ ngx_event_process_init, /* init process */ NULL, /* init thread */ NULL, /* exit thread */ NULL, /* exit process */ NULL, /* exit master */ NGX_MODULE_V1_PADDING};
先开始,把ngx_events_module和ngx_event_core_module搞混了,因为之前没有接触过nginx的模块,现在清楚了,当看到一个模块的时候,先看module type,ngx_event_core_module的type是NGX_EVENT_MODULE。而比较特殊,他是NGX_EVENT_MODULE最核心的module,同样的,我们看看ngx_event_core_module的内容
ngx_event_core_commands 存储着解析到”某些指令”回调”某些函数”。
ngx_event_core_module_ctx 则存储着模块配置的创建与初始化函数。
static ngx_command_t ngx_event_core_commands[] = { { ngx_string("worker_connections"), NGX_EVENT_CONF|NGX_CONF_TAKE1, ngx_event_connections, 0, 0, NULL }, { ngx_string("connections"), NGX_EVENT_CONF|NGX_CONF_TAKE1, ngx_event_connections, 0, 0, NULL }, { ngx_string("use"), NGX_EVENT_CONF|NGX_CONF_TAKE1, ngx_event_use, 0, 0, NULL }, { ngx_string("multi_accept"), NGX_EVENT_CONF|NGX_CONF_FLAG, ngx_conf_set_flag_slot, 0, offsetof(ngx_event_conf_t, multi_accept), NULL }, { ngx_string("accept_mutex"), NGX_EVENT_CONF|NGX_CONF_FLAG, ngx_conf_set_flag_slot, 0, offsetof(ngx_event_conf_t, accept_mutex), NULL }, { ngx_string("accept_mutex_delay"), NGX_EVENT_CONF|NGX_CONF_TAKE1, ngx_conf_set_msec_slot, 0, offsetof(ngx_event_conf_t, accept_mutex_delay), NULL }, { ngx_string("debug_connection"), NGX_EVENT_CONF|NGX_CONF_TAKE1, ngx_event_debug_connection, 0, 0, NULL }, ngx_null_command};ngx_event_module_t ngx_event_core_module_ctx = { &event_core_name, ngx_event_core_create_conf, /* create configuration */ ngx_event_core_init_conf, /* init configuration */ { NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL }};
另外,ngx_event_core_module还定义了2个函数。我们来看看这两个函数的调用情况
ngx_event_module_init, /* init module */ngx_event_process_init, /* init process */
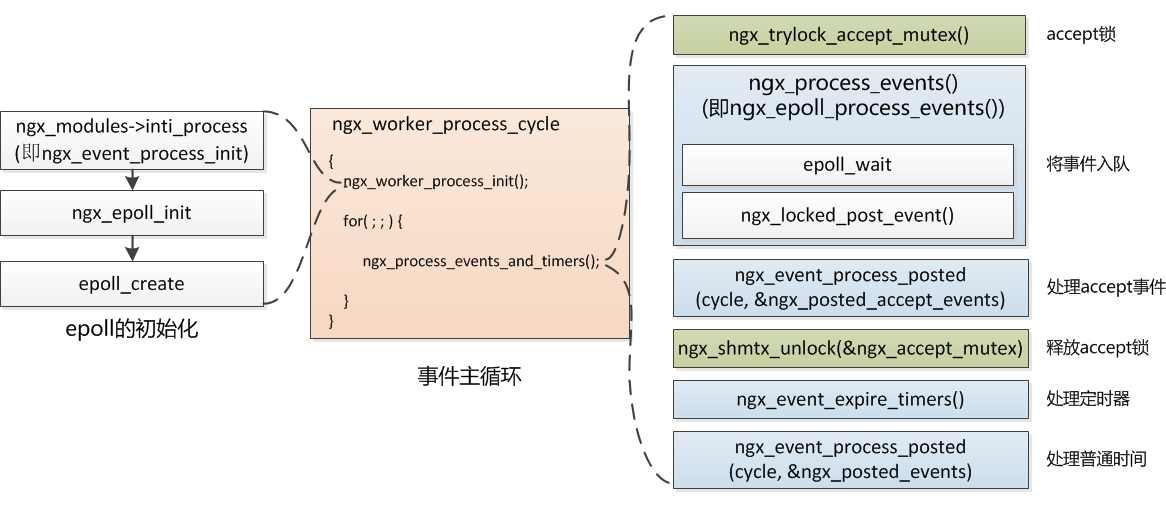
这两个函数的调用的时机,如下图所示:

ngx_event_module_init是在ngx_init_cycle被调用的,主要就是初始化模块的一些变量。
ngx_event_process_init则是在worker进程开始时被调用,之后便进入事件循环中,主要包括了负载均衡锁的初始化、定时器的初始化、连接池的初始化,以及在最后遍历所有modules来调用modules数组中的ngx_add_event函数,将事件添加到监听队列中。可以看到
#define ngx_process_changes ngx_event_actions.process_changes#define ngx_process_events ngx_event_actions.process_events#define ngx_done_events ngx_event_actions.done#define ngx_add_event ngx_event_actions.add#define ngx_del_event ngx_event_actions.del#define ngx_add_conn ngx_event_actions.add_conn#define ngx_del_conn ngx_event_actions.del_conn
这就是nginx事件模块的精华所在,通过这样的方式,就可以使得ngx_event_actions不同,采用不同的复用机制。可以参照下图,来理解ngx_event_core_module。
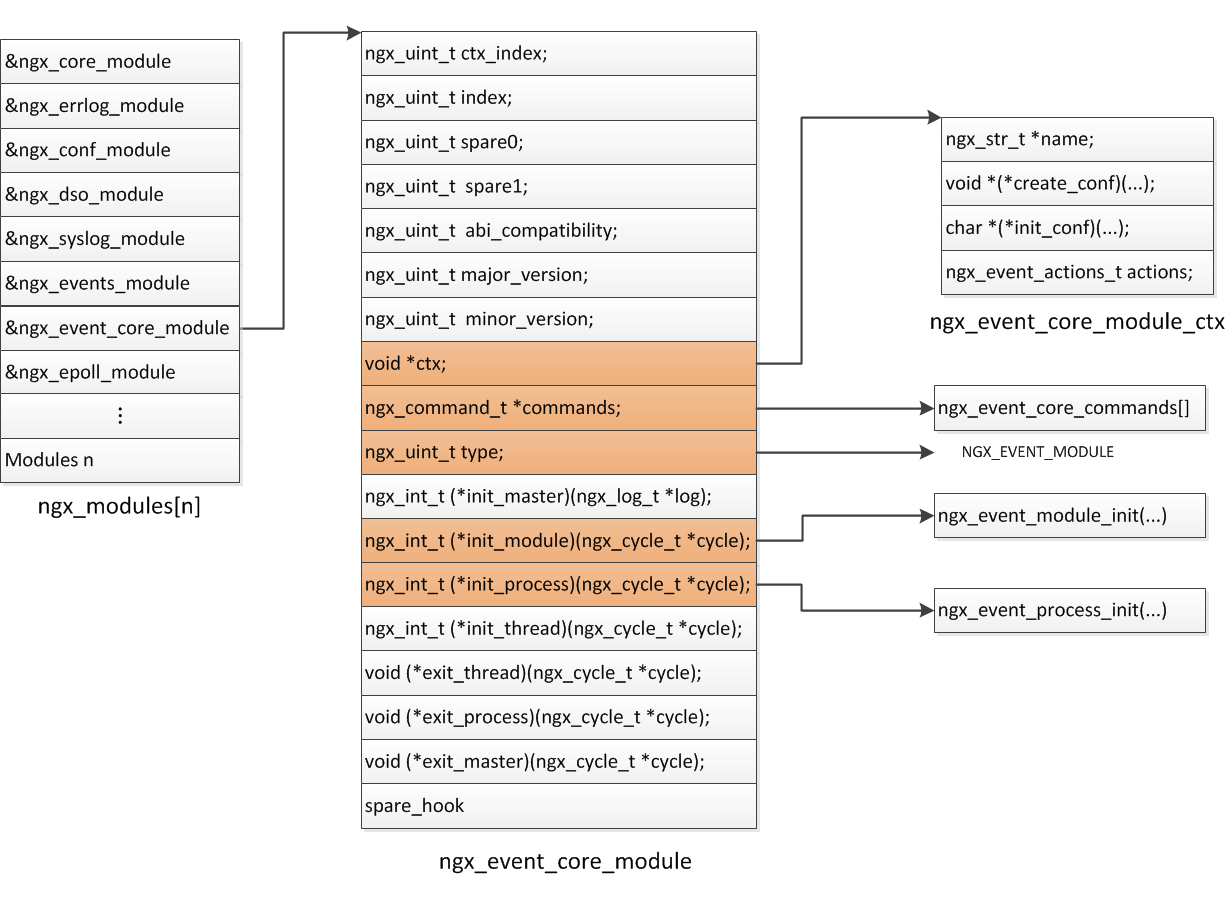
上面可以看到红色的部分是ngx_event_core_module有用的部分,需要强调的是这个事件模型只是用来初始化类似epoll的模块的,而自己是不做一些类似epoll事件循环的具体事件的。
至此,事件初始化就结束了,可以看到上面都是nginx通用的,不牵扯到具体的复用机制,后面会根据epoll来具体学习一下nginx事件循环。
]]>




























































































































































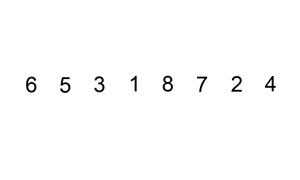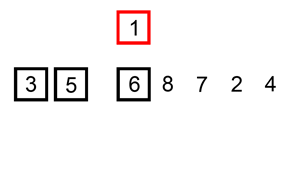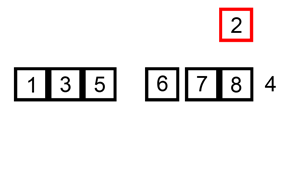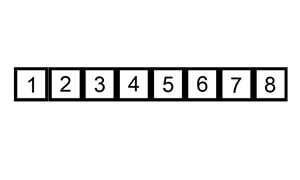
{kind=link}
{kind=link}
{kind=link}